最近在研究基于知识图谱的问答系统(Knowledge-based Question Answering,KBQA),这个领域的论文大多是基于 Freebase 的,所以就有机会了解一下 Freebase 。
Freebase
Freebase 作为典型的知识图谱,其采用结构化的数据形式(Wikipedia并不是)。Freebase 的内容主要源于 Wikipedia、NNDB、MusicBrainz 以及社会用户的贡献。该项目由 MetaWeb 公司在2005年启动,Google于2010年收购了该公司,并将 Freebase 作为Google知识图谱的核心部分。2016年8月,Google停止了对 Freebase 的维护,并将其整体迁移合并到 WikiData 项目中[1]。目前我知道的有以下几种方法获取到 Freebase 数据。
- Freebase Data Dump:Freebase 官网提供 N-Triple RDF格式(.nt文件)的数据压缩包的下载,整个压缩包30G,解压后300G+。下载后,可以用压缩软件解压,也可以通过编程工具(比如Java的GzipInputStream)边读取边解压。[2][3] (我并没有尝试这个方法)
- FB2M和FB5M:FB2M和FB5M是 Freebase 的两个子集,其中 FB2M 含有2M实体和5k实体关系,FB5M含5M实体和7k实体关系。CSDN上有这个两个文件的下载链接,其中使用 FB5M 还需要下载一个 FB5M 中 entity linke 到 entity name 的映射文件来将语料集的 link 替换掉[4](参考文章[4]中作者也提供了3个文件的下载链接,但可能过期)。下载之后三个文件都是 txt 文件,需要转换为 RDF 格式,文章后面会介绍如何转换为 RDF 格式并配合 Virtuoso 使用,我暂时只处理了 FB2M 数据,所以只说明 FB2M 数据的处理。
- FB15K和FB15K-237:FB15K 也是 Freebase 的子集,而FB15K-237 是 FB15K 的子集。这部分我暂时没有去了解,只提供一个下载链接Download FB15K-237 Knowledge Base Completion Dataset from Official Microsoft Download Center,和链接中对该数据集的一段描述:This dataset contains knowledge base relation triples and textual mentions of Freebase entity pairs, as used in the work published in (Toutanova and Chen CVSM-2015) and (Toutanova et al. Last published: October 30, 2015.
[1]段楠,周明 《智能问答》
[2]Freebase Data Dump结构初探 - 徒步浪人的专栏
[3]Freebase Data Dump 结构初探(二)——浅析元信息 - 徒步浪人的专栏
[4](freebase api关闭之后,该怎么做基于freebase的问答系统(KBQA)? - 知乎
利用rdflib库对数据进行处理
下载下来的FB2M数据的文件名是freebase-FB2M.txt是txt文件,需要转成RDF数据才能存入 Virtuoso 中,其中就是借助rdflib库将txt文件转化为nt文件。
rdflib的官方文档:rdflib 4.2.2 — rdflib 4.2.2 documentation。
安装
使用pip工具,在命令行运行pip install rdflib即可。
数据处理
观察freebase-FB2M.txt内的数据格式:1
2
3
4
5
6
7
8
9
10
11
12
13www.freebase.com/m/0n1vy1h www.freebase.com/people/person/gender www.freebase.com/m/05zppz
www.freebase.com/m/038b5bg www.freebase.com/music/release/track www.freebase.com/m/010bt_f www.freebase.com/m/010btzs
www.freebase.com/m/0cz9079 www.freebase.com/soccer/football_player/position_s www.freebase.com/m/02nzb8
www.freebase.com/m/03d1n81 www.freebase.com/organization/organization_founder/organizations_founded www.freebase.com/m/04hk45
www.freebase.com/m/03byqr1 www.freebase.com/cvg/computer_videogame/cvg_genre www.freebase.com/m/033th www.freebase.com/m/0_678
www.freebase.com/m/0n5xzdf www.freebase.com/people/person/place_of_birth www.freebase.com/m/0c_m3
www.freebase.com/m/02vwbkk www.freebase.com/people/person/nationality www.freebase.com/m/01mk6
www.freebase.com/m/02hl5l7 www.freebase.com/cvg/game_version/platform www.freebase.com/m/050xd
www.freebase.com/m/0b70yxd www.freebase.com/film/film/genre www.freebase.com/m/07s9rl0
www.freebase.com/m/0nd_0ll www.freebase.com/people/person/gender www.freebase.com/m/02zsn
www.freebase.com/m/0g5b3gn www.freebase.com/people/person/gender www.freebase.com/m/05zppz
www.freebase.com/m/0h972x8 www.freebase.com/music/album/album_content_type www.freebase.com/m/02jbfk
www.freebase.com/m/0l__j www.freebase.com/common/topic/notable_types www.freebase.com/m/02scvxs
三个URI为一行,对应一个三元组。
1 | # encoding=utf-8 |
参考文章:
将Freebase导入Virtuoso
在安装完Virtuoso后需要做的就是将30G的Freebase-rdf-latest.gz导入,主要是按照Virtuoso Freebase Setup · sameersingh/nlp_serde Wiki介绍的步骤进行,首先gunzip freebase-rdf-*.gz解压缩,需要一些时间。之后就是将三元组导入Virtuoso,先使用isql-vt 1111 dba dba启动isql工具,这里使用isql-vt而不是isql是因为为了解决与ODBC的isql冲突而将virtuoso的isql改了名,具体可见《Virtuoso的安装与使用》中的服务器上virtuoso的安装最后部分。将load任务加入到load_list中,SQL> ld_dir('.', 'freebase-rdf-*', 'http://freebase.com');。SQL> select * from DB.DBA.load_list;查看数据集加载情况,在认为加载数据集结束后也可以通过另开isql窗口运行该指令来查看是否加载完成,以下图为例。
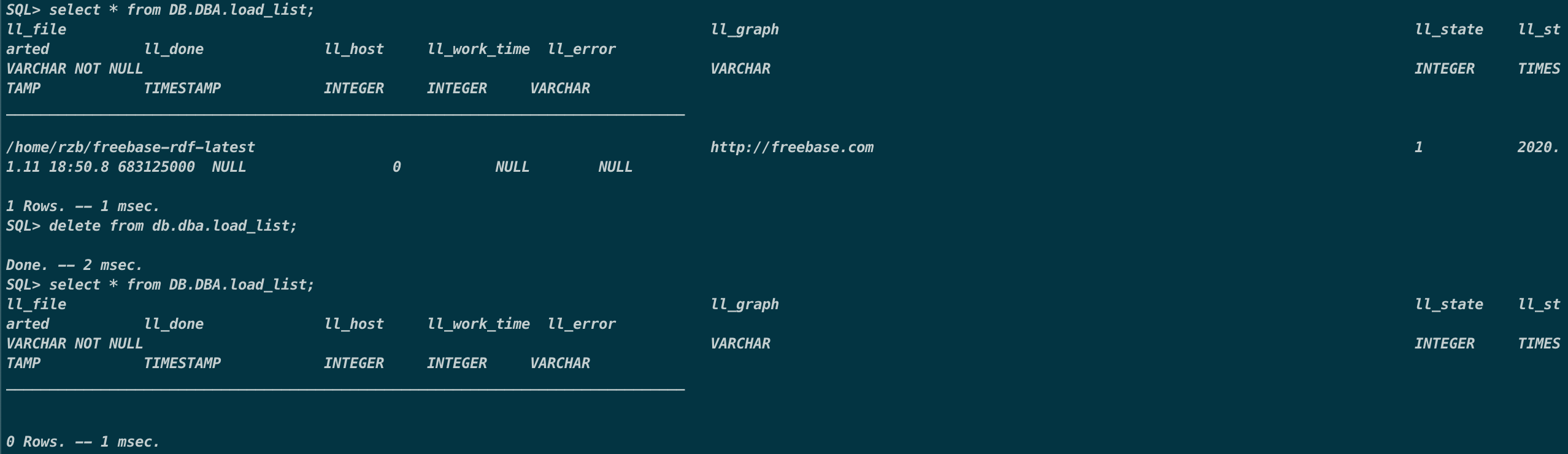
ll_state字段有三个值:0表示数据集还没有加载;1表示数据集正在加载;2表示数据集已经加载完成。
然后通过SQL>rdf_loader_run();进行大文件数据的加载。因为freebase很大,所以会比较漫长,如果加载成功,会有一个花费时间的显示。在导入完成后,需要清理一下load_list,否则下次装载其它文件时,load_list里面的文件还会导入,清理的指令是delete from db.dba.load_list;。最后可以通过SQL> SPARQL SELECT COUNT(*) { ?s ?p ?o };查看三元组数量。
如果将来想要删除virtuoso中的freebase的话,可以使用指令SQL> SPARQL CLEAR GRAPH <http://freebase.com>;
